你的 AI 代理正淹没在
CLI 噪音中。 解决它。
rtk 在命令输出进入上下文窗口之前对其进行压缩。 更好的推理。更长的会话。更低的成本。
Why RTK? The numbers.
89% noise reduction measured across 2,900+ real-world dev commands: cargo test 91.8%, git status 80.8%, find 78.3%, grep 49.5%. Free, open source (Apache 2.0, Rust).

📊 RTK Token Savings
════════════════════════════════════════
Total commands: 2,927
Input tokens: 11.6M
Output tokens: 1.4M
Tokens saved: 10.3M (89.2%)
By Command:
────────────────────────────────────────
Command Count Saved Avg%
rtk find 324 6.8M 78.3%
rtk git status 215 1.4M 80.8%
rtk grep 227 786.7K 49.5%
rtk cargo test 16 50.1K 91.8%
$
- Claude Code
- Cursor
- Aider
- Gemini CLI
- OpenAI Codex
- Cline
- Windsurf
- GitHub Copilot

当今 AI 编程的问题
代理执行的每个命令都会用噪音污染上下文窗口。这会产生以下代价。
上下文污染
你的 200K 上下文窗口不是无限的。当 cargo test 输出 5000 个模板 token 时,就少了 5000 个用于推理实际代码的 token。
context_quality: degraded ▼会话太短
上下文溢出,代理重启,你失去了线索。在固定费率计划上,你会比应该的速度快 40% 达到速率限制。
session_remaining: 32% ▼成本爆炸
在按 token 付费的设置中(API、Gemini CLI、Aider),70% 的账单是 LLM 不需要的噪音。10 人团队每月浪费约 $1,750。
token_waste: $1,750/mo ▲
查看差异
真实输出,真实节省。实际命令的并排对比。

真实节省
满意的开发者通过 rtk gain 的真实反馈。
开发者反馈
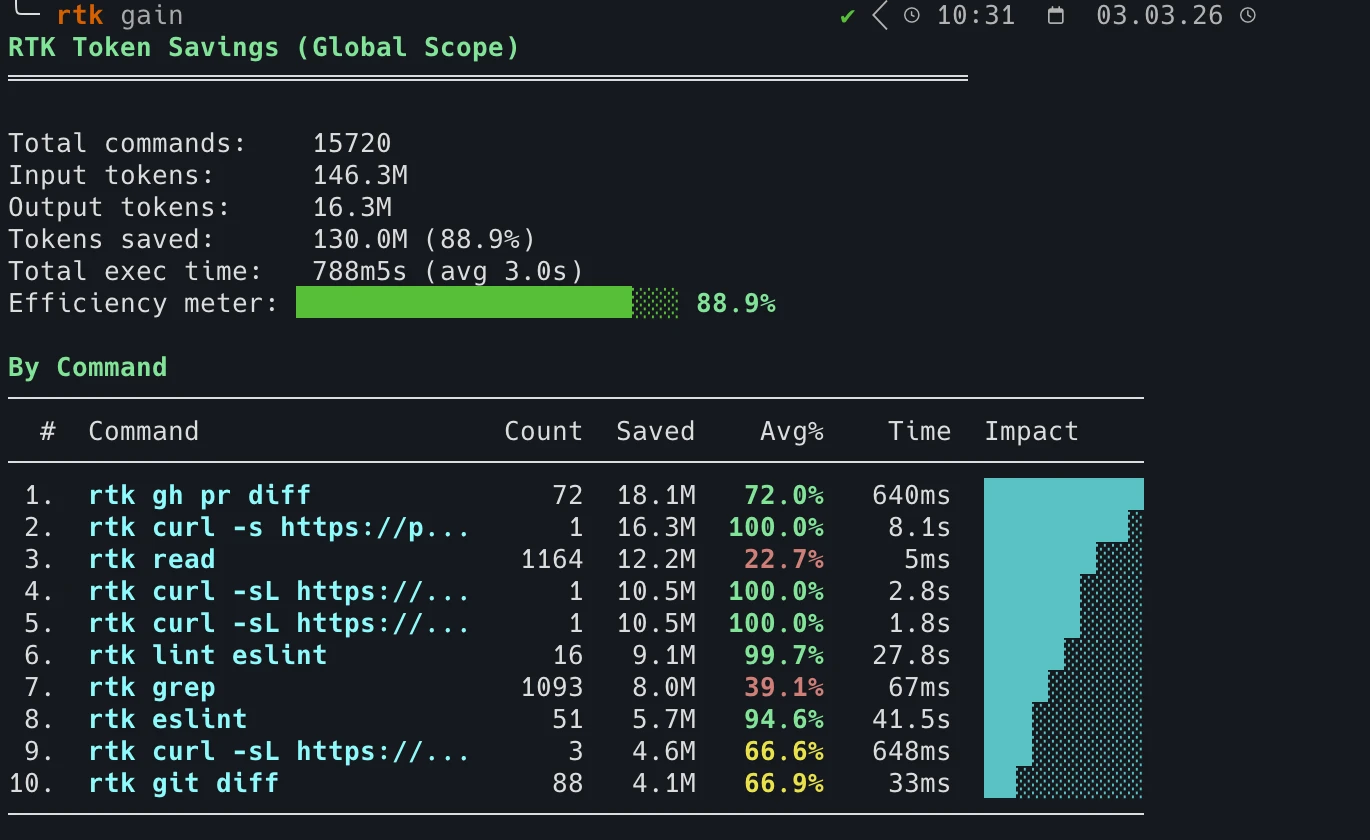
日常使用几周后:15,720 个命令,节省 1.38 亿 token。运行 rtk gain 查看你的。
详细明细
按命令的每日、每周和每月统计。跟踪你的节省。
Per-command analytics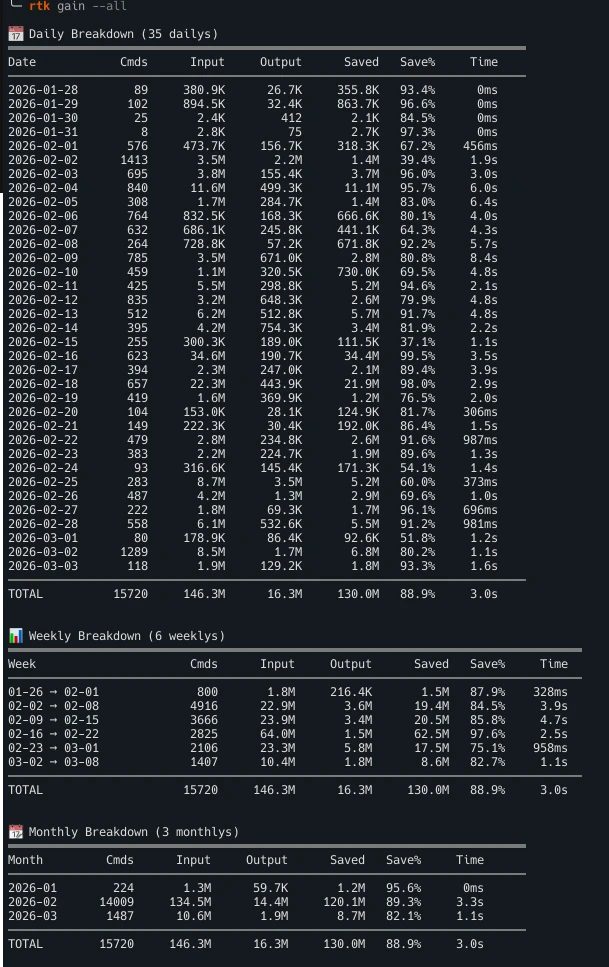
RTK Cloud
对团队 AI 编程成本的可见性和控制。了解浪费。解决它。
Token 分析
按开发者、项目、工具的仪表盘
团队节省报告
"你的团队本月节省了 $4,200"
速率限制警报
监控和智能通知
企业控制
SSO、审计日志、合规
开源免费。团队从 $15/开发者/月 起。
0 团队在等待列表中
无垃圾邮件。上线时发一封邮件。

30 秒开始
安装,激活自动重写钩子,每个命令自动压缩。
快速安装
Linux 和 macOS 一行命令
curl -fsSL https://raw.githubusercontent.com/rtk-ai/rtk/refs/heads/master/install.sh | sh Via Homebrew
macOS & Linux
brew install rtk-ai/tap/rtk brew upgrade rtk-ai/tap/rtk 然后激活自动重写钩子
rtk init --global 在 Claude Code settings.json 中安装 PreToolUse 钩子——每个 Bash 调用都会自动重写。 完整安装指南 →
rtk init --global --agent cursor 配置 Cursor 的 .cursorrules,将 Bash 命令通过 rtk 传输。 完整安装指南 →
rtk init --global --agent <name> 安装全局 shell 钩子——适用于 Aider、Gemini CLI、Codex、Windsurf 以及任何终端 AI 工具。 完整安装指南 →
curl ... | sh rtk init --global rtk gain 

Frequently asked questions
What is RTK (Rust Token Killer)?
RTK is an open-source CLI tool that compresses command outputs before they reach the AI context window. It reduces token usage by 60-90% with zero configuration changes, enabling longer AI coding sessions and lower API costs. RTK is written in Rust, Apache 2.0 licensed, and works transparently with Claude Code, Cursor, and any terminal-based AI assistant.
How many tokens does RTK actually save?
Based on measurements across 2,900+ real-world commands, RTK removes an average of 89% of CLI output noise. Command-level savings: cargo test (91.8% savings), git status (80.8%), find (78.3%), grep (49.5%). A developer who ran 15,720 commands saved 138 million tokens over several weeks, tracked live via rtk gain.
Is RTK free? Are there usage limits?
RTK is completely free. It is open source under the Apache 2.0 license, with source code available on GitHub at github.com/rtk-ai/rtk. There are no usage limits, no API keys required, no telemetry, and no accounts. RTK Cloud (waitlist) will offer additional team features.
Which AI coding tools and commands does RTK support?
RTK works with Claude Code (Anthropic), Cursor, Gemini CLI, Aider, and any AI assistant that reads terminal output. It supports all major CLI commands: cargo test, pytest, go test, git diff, git status, git log, grep, find, ls, pnpm list, tsc, eslint, prisma, docker, kubectl, and more.
How does RTK work without changing my workflow?
Running rtk init --global installs a PreToolUse hook in Claude Code that automatically rewrites Bash commands to rtk equivalents at the proxy layer. You continue using your normal commands. RTK intercepts and compresses the output before it enters the context window, with no manual changes to prompts or workflows needed.
Does RTK affect code quality or AI reasoning accuracy?
No. RTK removes verbose boilerplate and repetitive output noise, not meaningful content. Test failures, error messages, diffs, and stack traces are preserved in full. The AI receives the same essential information with 89% less noise, which typically improves reasoning quality by reducing context pollution.