Tu agente IA se ahoga
en ruido del CLI. Arréglalo.
rtk comprime las salidas de comandos antes de que lleguen a la ventana de contexto. Mejor razonamiento. Sesiones más largas. Menores costos.
Why RTK? The numbers.
89% noise reduction measured across 2,900+ real-world dev commands: cargo test 91.8%, git status 80.8%, find 78.3%, grep 49.5%. Free, open source (Apache 2.0, Rust).

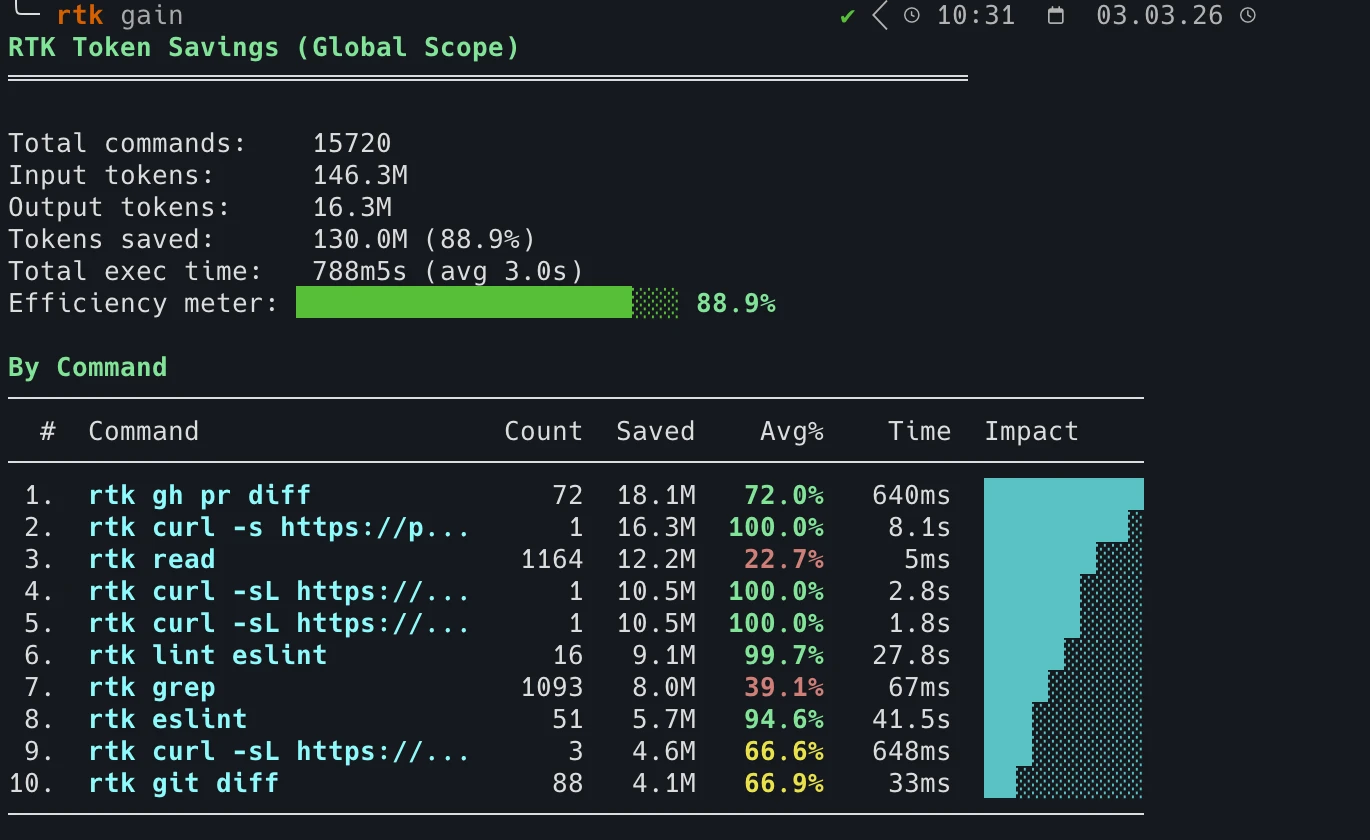
📊 RTK Token Savings
════════════════════════════════════════
Total commands: 2,927
Input tokens: 11.6M
Output tokens: 1.4M
Tokens saved: 10.3M (89.2%)
By Command:
────────────────────────────────────────
Command Count Saved Avg%
rtk find 324 6.8M 78.3%
rtk git status 215 1.4M 80.8%
rtk grep 227 786.7K 49.5%
rtk cargo test 16 50.1K 91.8%
$
- Claude Code
- Cursor
- Aider
- Gemini CLI
- OpenAI Codex
- Cline
- Windsurf
- GitHub Copilot

El problema del coding con IA hoy
Cada comando que ejecuta tu agente contamina la ventana de contexto con ruido. Esto es lo que te cuesta.
Contaminación del contexto
Tu ventana de 200K tokens no es infinita. Cuando cargo test vuelca 5.000 tokens de boilerplate, son 5.000 tokens menos para razonar sobre tu código.
context_quality: degraded ▼Sesiones demasiado cortas
El contexto se desborda, el agente reinicia, pierdes el hilo. Con tarifas planas, alcanzas los límites un 40% más rápido.
session_remaining: 32% ▼Costos que explotan
Con pago por token (API, Gemini CLI, Aider), el 70% de tu factura es ruido que el LLM no necesita. Un equipo de 10 desperdicia ~$1.750/mes.
token_waste: $1,750/mo ▲
Mira la diferencia
Salidas reales, ahorros reales. Comparación lado a lado con comandos reales.

Ahorros reales
Resultado real de un desarrollador satisfecho con rtk gain.
Feedback de un desarrollador
Tras unas semanas de uso diario: 15.720 comandos, 138M tokens ahorrados. Ejecuta rtk gain para ver los tuyos.
Desglose detallado
Estadísticas diarias, semanales y mensuales por comando. Rastrea tus ahorros.
Per-command analytics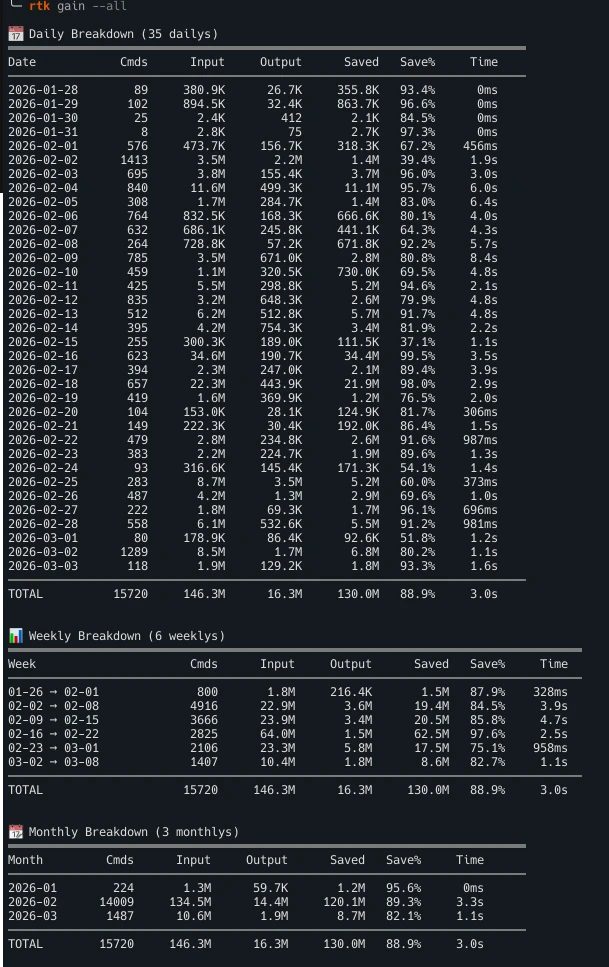
RTK Cloud
Visibilidad y control sobre los costos de IA de tu equipo. Sabe qué se desperdicia. Corrígelo.
Analítica de tokens
Dashboard por dev, por proyecto, por herramienta
Informes de ahorro
"Tu equipo ahorró $4.200 este mes"
Alertas de límites
Monitoreo y notificaciones inteligentes
Controles empresariales
SSO, logs de auditoría, cumplimiento
Gratis para open-source. Equipos desde $15/dev/mes.
0 equipos en lista de espera
Sin spam. Un solo email al lanzamiento.

Empieza en 30 segundos
Instala, activa el hook auto-rewrite, y cada comando se comprime automáticamente.
Instalación rápida
Una línea para Linux y macOS
curl -fsSL https://raw.githubusercontent.com/rtk-ai/rtk/refs/heads/master/install.sh | sh Via Homebrew
macOS & Linux
brew install rtk-ai/tap/rtk brew upgrade rtk-ai/tap/rtk Luego activa el hook auto-rewrite
rtk init --global Instala hook PreToolUse en Claude Code settings.json — cada llamada Bash se reescribe automáticamente. Guía completa →
rtk init --global --agent cursor Configura .cursorrules de Cursor para enrutar comandos Bash a través de rtk. Guía completa →
rtk init --global --agent <name> Instala un hook de shell global — funciona con Aider, Gemini CLI, Codex, Windsurf y cualquier herramienta IA terminal. Guía completa →
curl ... | sh rtk init --global rtk gain 

Tu IA no necesita
leer todo eso.
Instala rtk. Mejor código, sesiones más largas, menores costos.
Frequently asked questions
What is RTK (Rust Token Killer)?
RTK is an open-source CLI tool that compresses command outputs before they reach the AI context window. It reduces token usage by 60-90% with zero configuration changes, enabling longer AI coding sessions and lower API costs. RTK is written in Rust, Apache 2.0 licensed, and works transparently with Claude Code, Cursor, and any terminal-based AI assistant.
How many tokens does RTK actually save?
Based on measurements across 2,900+ real-world commands, RTK removes an average of 89% of CLI output noise. Command-level savings: cargo test (91.8% savings), git status (80.8%), find (78.3%), grep (49.5%). A developer who ran 15,720 commands saved 138 million tokens over several weeks, tracked live via rtk gain.
Is RTK free? Are there usage limits?
RTK is completely free. It is open source under the Apache 2.0 license, with source code available on GitHub at github.com/rtk-ai/rtk. There are no usage limits, no API keys required, no telemetry, and no accounts. RTK Cloud (waitlist) will offer additional team features.
Which AI coding tools and commands does RTK support?
RTK works with Claude Code (Anthropic), Cursor, Gemini CLI, Aider, and any AI assistant that reads terminal output. It supports all major CLI commands: cargo test, pytest, go test, git diff, git status, git log, grep, find, ls, pnpm list, tsc, eslint, prisma, docker, kubectl, and more.
How does RTK work without changing my workflow?
Running rtk init --global installs a PreToolUse hook in Claude Code that automatically rewrites Bash commands to rtk equivalents at the proxy layer. You continue using your normal commands. RTK intercepts and compresses the output before it enters the context window, with no manual changes to prompts or workflows needed.
Does RTK affect code quality or AI reasoning accuracy?
No. RTK removes verbose boilerplate and repetitive output noise, not meaningful content. Test failures, error messages, diffs, and stack traces are preserved in full. The AI receives the same essential information with 89% less noise, which typically improves reasoning quality by reducing context pollution.